How Can Data Science Help Supply Chain & Logistics Companies?
-

Pratik Roy

Since data is the fundamental building block of information flow, it should go without saying that data is one of the pillars of supply chain management. : global networks used to deliver goods and services through engineered flows of information, physical goods, and cash

The Supply Chain is the backbone and high-value use-cases
The numerous different global supply chain crises that have occurred over the past few years have shown that there is at least one thing that organizations need to be aware of: there is an increasing need for supply chains to be reconfigurable so that they can respond to changes in demand patterns as well as disruptions in the availability of resources.
The agile development and deployment of high-value, tailored use cases to support Supply Chain operations turned out to be an effective strategy for dealing with this problem.
These solutions address the functional gaps left by more comprehensive software in various ways, including dashboards, tailored business planning tools, Artificial intelligence models, low-code apps, and automated workflows.
Legacy applications like ERPs, APS, WMS, or TMS continue to be the backbone of supply chain management activities in this type of architecture.
With decades of experience incorporated into each solution’s functions, there is no question as to the applicability of these software solutions for managing both master data and transactional data in accordance with Supply Chain Management best practices.
These monolithic solutions must be supplemented with focused business tools to achieve the necessary agility over time. Benefits result when such instruments:
- Effectively increase the effectiveness of Supply Chain procedures (a custom forecasting algorithm is one use-case that demonstrates this)…
- Or offer a competitive advantage (for instance, a new vendor-managed inventory solution made possible by an SKU-level shortage prediction).
- Quick deployment and development (in under a few weeks or months).
- Constantly updated to meet the most recent specifications established by supply chain reality
What are the Use Cases of Data Science for the Supply Chain?
If this method applies to all operations processes (purchasing, finance, human resources, manufacturing, etc.), High-value use cases can grow particularly well in supply chain & Logistics Industries. We at Brainvire think that Data Science methods and equipment are a crucial component of this strategy.
We view data science as the collection of components that must be used in unison to achieve this goal, including data visualization tools, data platforms, advanced analytics, AI/ML algorithms, etc.
In terms of maturity (or complexity), data-driven solutions for supply chains can be conceptually divided into four groups:
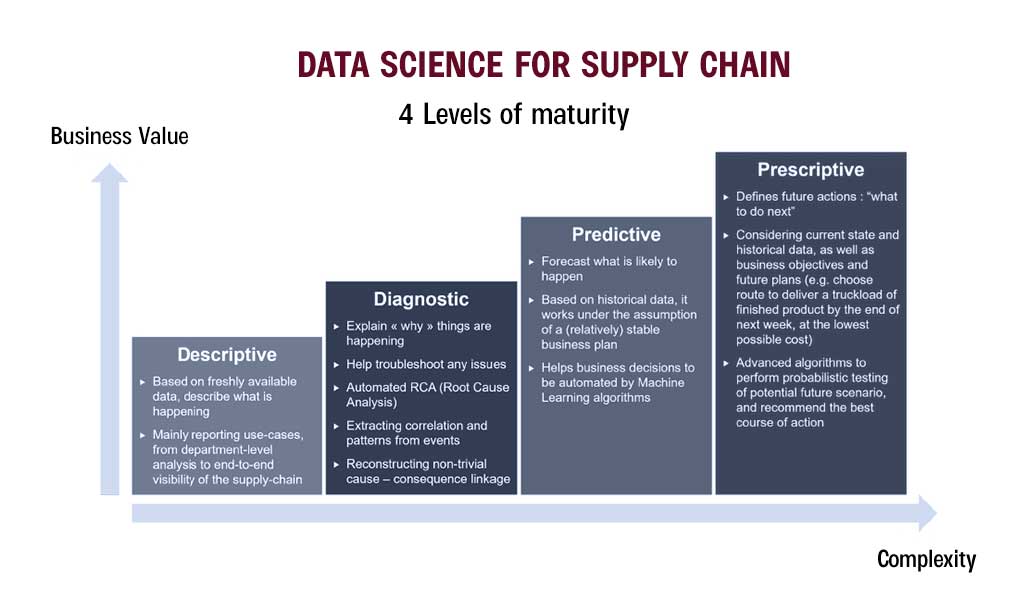
Descriptive: for instance, reporting on stock conditions quickly for all DCs and Stores.
Diagnostic: examples include establishing a connection between a delay in a specific raw material and the client orders that follow in its path.
Predictive: as in the probabilistic forecasting of expected short-term demand volumes.
Prescriptive: for instance, a suggestion to place a second purchase order with a secondary supplier due to I a potential rise in demand, (ii) a delay anticipated by the original supplier, and (iii) a dearth of worldwide inventory for the matching finished goods.
The most developed use cases in the above instances, it is evident, combine intelligence from lower-level applications. However, even the less developed use cases frequently demonstrate a clear return on investment before acting as a stepping stone to more sophisticated applications.
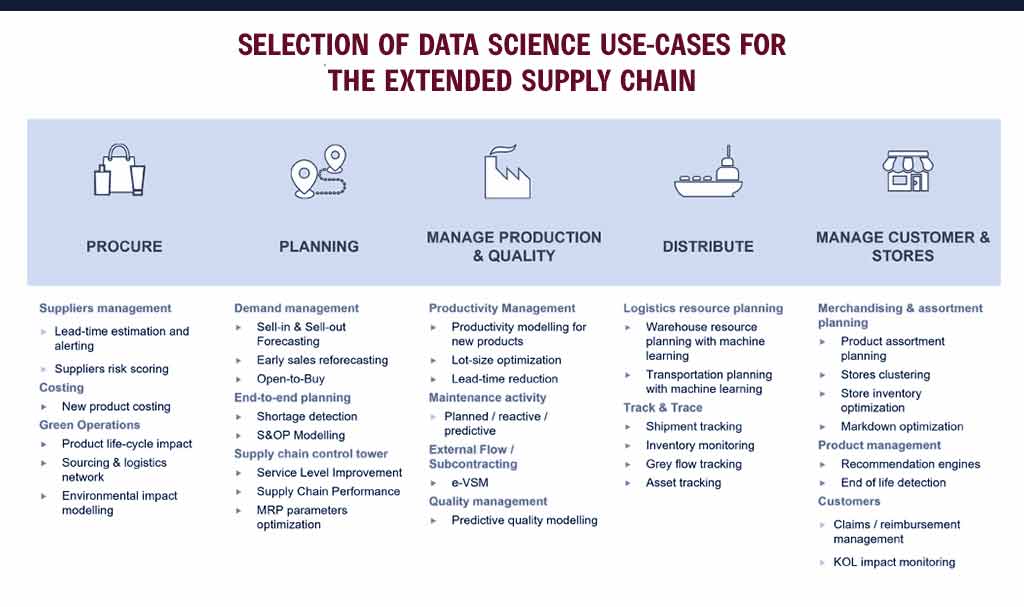
More concretely, the accompanying figure depicts a number of Supply Chain use-cases with Data Science approaches at their core that we’ve experienced and implemented in our clients’ businesses. This list is by no means exhaustive or industry-specific.
How does the Selection of Data Science use-cases for the extended Supply Chain?
A stepping stone for use cases is data platforms.
This data-driven strategy results from the Data’s presence, accessibility, quality, and availability.
The needs of this strategy are typically significantly out of sync with the day-to-day Data Management in place in enterprises. As a result, the Enterprise Data Platform positions itself as a collection of ideas and resources cooperating to close this gap, bringing about and maintaining commercial use cases.
This is how we envision such a platform: as the “single source of truth” for all business tools and use cases; it combines technology elements, supporting teams, and appropriate data governance.
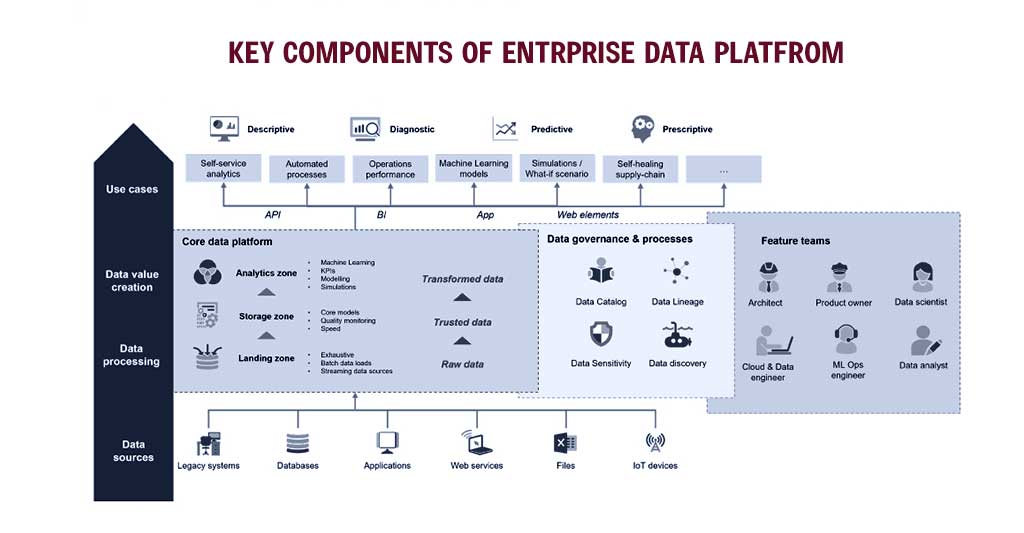
Both Data teams and Supply Chain teams share converging aspirations from the perspective of the Enterprise Data Platform :
. Building a single source of truth for business domains, exposing high-quality data models. For example, the table object “sales forecast” should be created with the expertise of demand planners and then made 5 available to the rest of the Supply Chain stakeholders, including Purchasing, Marketing, Merchandising, Product Development, and so on.
. Connecting to many Data sources, getting the data out of the systems of records, and making it available to various users. For instance, enabling end-to-end visibility on a global Supply Chain by ingesting data from all the country-level ERP systems.
. Building an abstraction layer between the legacy IT and analytical tools, therefore decoupling software and IT projects from the business side. For instance, you can use APS tooling without completely redesigning your demand and supply planning KPIs.
Organizational / people consequences
The Enterprise Data Platform also provides the more real benefit of having a workable base to establish a more data-driven culture, even if particular use cases deliver their own clearly defined ROI. Teams from the supply chain can get a good start on this project because Excel has long been the go-to tool for supply chain analysts, and data analysis skills are required for the job.
Supply teams are recognized for being among the first to establish data lakes and warehouses and for making multiple uses of BI tools, more so than other departments within the company.
Offering supply chain personnel highly accessible Data (curated or not) spanning the firm’s activities, along with cutting-edge and potent tools to enable flexible data exploration, analysis, and modelling, can yield even more significant value. We categorise a number of products under the umbrella of “self-service Data analytics” for corporate customers, including:
- Software for data visualization (Power BI, Tableau, Qlikview, Looker, etc.)
- SQL editors that allow for collaboration along with spreadsheets, notebooks, or both (Databricks, Azure Data Studio, PopSQL)
- Or all-in-one systems (Dataiku, Alteryx, DataRobot) that can assist in the implementation of AI models.
Data teams would expect to assist Supply Chain teams in expanding their use of these tools, as this should be conglomerate effects on the creation of new use cases and the delivery of value to the enterprise.
As a result, Data Feature teams manage the platform’s architecture, keep an eye on the platform’s quality (freshness, completeness, validity, and coherence), provide self-service users with training materials, and create high-value data products.
To realize this objective, the feature teams and supply chain teams must work closely together:
. Data teams can “push” use cases that are more complicated to solve on the one hand by utilizing their specialised profiles (Data Engineers, Data Scientists, UI Experts, etc.). For instance, a lead-time prediction model addressing purchase orders to suppliers and subcontractors or a machine learning forecasting method for new product potential prediction. On top of the data core models made available by the feature teams, Supply Chain teams can, however, construct their use cases. For example, a stock policy simulation model and accompanying stock analysis dashboard.
Supply Chain teams can create a preliminary version of a use case between the two before relying on the Data team to broaden its scope and bring it up to the required Data standards for usage across the entire company.
For example, a dashboard that supports the S&OP process can also be tested on a single business unit before being used more widely.
Conclusion
Supply Chain teams have much to gain from the contemporary Data Stack and Data Science methodology, which produces use cases with high-added value and make Supply Chains adaptable. The Supply Chain and Data Features teams must work together to realize the vision of the Enterprise Data Platform. Collaboration with data teams will enable you to provide projected benefits on use cases with increasing complexity on a durable platform as a supply chain practitioner. Working with Supply Chain teams will advance your path as a Data Leader toward a genuinely end-to-end platform, allowing you to address a range of use cases.

Related Articles
-
 Why the Next-Generation Power BI is a Potent Vehicle for Your Business
Why the Next-Generation Power BI is a Potent Vehicle for Your BusinessBusiness Intelligence (BI) and Big Data have been the buzzwords that are steering the business ahead. However, business enterprises are leveraging further with a new digital transformation trend that is
-
 The Microsoft Power Platform – Empowering Millions of People to Achieve more
The Microsoft Power Platform – Empowering Millions of People to Achieve moreBy 2023, 500 million apps will be developed to drive organizational transformation and productivity. Microsoft is at the forefront of this digital transformation, aiming to assist businesses to reimagine how
-
 The SharePoint Challenge: Detail Guide To Implement and Use SharePoint
The SharePoint Challenge: Detail Guide To Implement and Use SharePointMicrosoft SharePoint implementation provides a central hub for enterprise content. It’s used to access and share documents, blogs, websites, PowerPoint presentations, etc. Various SharePoint Platforms, like Power Automate, use low-code


