Exploring Python’s Leading Role in Data Analytics and Its Key Advantages
-

Saumil Kalaria

In the era of data-driven decision-making, Python has emerged as a game-changer in data analytics. Its versatile libraries and robust capabilities transform how industries approach data, making it an indispensable tool for data scientists and analysts. Python’s widespread adoption across various domains is a testament to its effectiveness in handling data analytics tasks, from basic statistical analysis to complex machine learning models.
As businesses strive to harness the power of data, Python’s role has become increasingly pivotal. Its ability to process, analyze, and visualize data efficiently has revolutionized how organizations make informed decisions. By delving into Python’s dominance in data analytics, we can uncover why it stands out among other programming languages and how it continues to drive innovation in the field.
What is Python and How Does It Powers Data Analytics?
Guido van Rossum created Python, an object-oriented, interpreted programming language, in 1991. Its syntax is straightforward yet powerful, making it simple to learn and read. In addition to object-oriented programming, Python supports a wide range of programming paradigms, including functional and procedural programming. It can serve as an extension language for applications that require a programmable interface. Python is portable and adaptable since it can operate on Unix variations such as Windows, macOS, and Linux.
Data analysts often know one or more programming languages. Python is still one of the most popular coding languages among data scientists and analysts due to its ease of use and numerous libraries suitable for data analytics. Python is extremely legible, saving data analysts and engineers time by reducing the amount of code required to execute tasks.
Here’s a closer look at the key factors contributing to Python’s dominance in data analytics:

Enhanced Readability and Simplicity
Python’s straightforward syntax allows for clear and concise code, enhancing readability and reducing new users’ learning curve. Its simplicity facilitates rapid development and prototyping, enabling data scientists to focus on solving complex problems rather than getting bogged down by intricate syntax.
Expansive Ecosystem of Data Science Libraries
Python boasts a rich ecosystem of libraries tailored for data science tasks. Some of the most prominent libraries include:
- Pandas: Essential for data manipulation and analysis, Pandas provide data structures and functions designed to work seamlessly with structured data
- NumPy: This library supports numerical computing with powerful array objects and mathematical functions
- Matplotlib: A versatile plotting library that enables users to create static, animated, and interactive visualizations
- Seaborn: Built on Matplotlib, Seaborn offers a high-level interface for drawing attractive and informative statistical graphics
- SciPy: This library complements NumPy by providing additional scientific and technical computing functionality
These libraries empower analysts to efficiently perform data manipulation, numerical computing, and visualization.
Supportive Community and Resources
Python’s active community and abundant resources are pivotal to its success. The extensive support from forums, tutorials, and documentation ensures that users can access knowledge and solutions. This collaborative environment fosters continuous improvement and innovation within the Python ecosystem.
Empowering Machine Learning and Deep Learning
Python’s ecosystem extends to machine learning and deep learning, with libraries such as:
- TensorFlow: An open-source framework for building and deploying machine learning models, TensorFlow supports both deep learning and traditional machine learning techniques
- PyTorch: Another popular deep learning library, PyTorch is known for its dynamic computation graph and ease of use in research and development
These libraries facilitate rapid prototyping and integration of advanced machine learning models, further enhancing Python’s role in data analytics.
Seamless Integration with Other Languages
Python’s interoperability with other programming languages enhances its versatility. It can easily integrate with languages like:
- C and C++: For performance-critical applications
- Java: For enterprise-level solutions
- R: For statistical analysis and data visualization
This seamless integration allows Python to complement existing systems and leverage the strengths of other languages.
Performance and Scalability
Python’s performance and scalability are crucial for handling big data. With tools like Dask and PySpark, Python can efficiently process large datasets and perform distributed computing. These tools enable Python to manage data at scale, making it suitable for big data analytics.
Versatility Beyond Data Science
Python’s versatility extends beyond data science, offering capabilities in various domains:
- Web Development: Frameworks like Django and Flask enable rapid development of web applications
- Automation: Python’s scripting capabilities are ideal for automating repetitive tasks
- Scientific Computing: Libraries like SciPy support complex scientific computations
- Natural Language Processing (NLP): Libraries such as NLTK and SpaCy facilitate language processing tasks
- Game Development: Python can be used for developing games with libraries like Pygame
This broad applicability underscores Python’s dominance as a programming language and its impact on diverse fields.
Maximizing Data Science Capabilities through Python Development Services and Solutions

Its development services further amplify Python’s capabilities in data science. These services enable organizations to leverage Python’s full potential in various aspects of data analytics:
- Data Engineering
Python’s role in data engineering involves designing and building pipelines that ensure efficient data collection, storage, and processing. Tools like Apache Airflow and Luigi facilitate workflow automation and orchestration, enhancing data engineering processes.
- Advanced Analytical Capabilities
Python’s advanced analytical capabilities include statistical analysis, exploratory data analysis (EDA), and hypothesis testing. Libraries like StatsModels and Scikit-learn provide tools for performing sophisticated statistical analyses and developing predictive models.
- Data Exploration and Analysis
Python excels in data exploration and analysis with its robust data manipulation and visualization libraries. Analysts can use Pandas for data wrangling, Matplotlib and Seaborn for visualization, and Jupyter notebooks for interactive exploration and documentation. In addition to working with internal datasets, analysts often enrich their analysis with publicly available web data. A web scraping API can help automate the extraction of such data and integrate it into Python-based workflows.
- Machine Learning Model Development
Python’s machine learning libraries, such as Scikit-learn, TensorFlow, and PyTorch, enable the development and training of machine learning models. These libraries support various algorithms and techniques, from classification and regression to clustering and dimensionality reduction.
- Model Deployment and Integration
Python’s versatility extends to model deployment and integration. Tools like Flask and FastAPI facilitate the deployment of machine learning models as APIs, enabling seamless integration with web applications and other systems.
Predictions for the Future of Python in Big Data Analytics
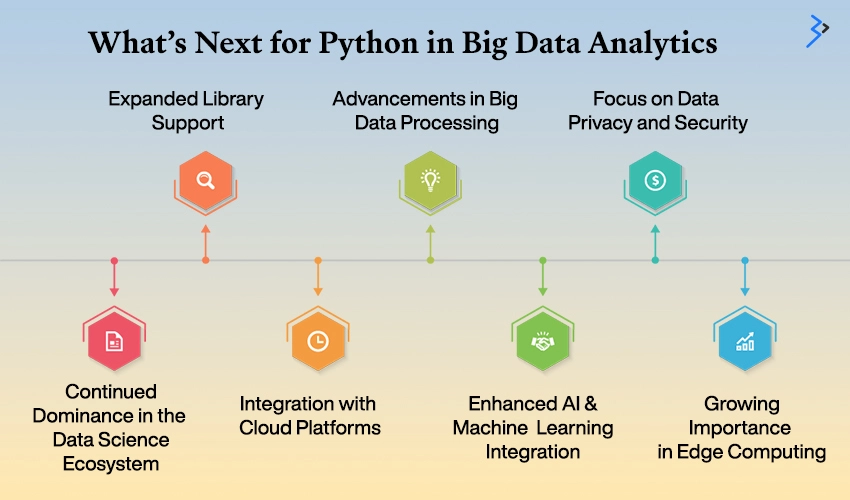
Python’s role in big data analytics is expected to evolve as data grows in volume and complexity. Here are some predictions for Python’s future in this domain:
Continued Dominance in the Data Science Ecosystem
Python is likely to maintain its dominance in the data science ecosystem due to its extensive libraries, supportive community, and versatility. As data analytics becomes more integral to decision-making, Python’s role as a primary tool for data scientists will continue to grow.
Expanded Library Support
Python’s library ecosystem is expected to grow, with new libraries and tools emerging to address evolving data analytics needs. Enhanced support for specialized tasks, such as geospatial analysis and advanced machine learning techniques, will further solidify Python’s position.
Integration with Cloud Platforms
Python’s integration with cloud platforms will play a crucial role in its future. Cloud-native Python frameworks and serverless computing solutions will enable scalable and cost-effective data processing and analytics.
Advancements in Big Data Processing
Python will likely see big data processing capabilities advancements, including distributed computing and real-time analytics improvements. Enhanced support for frameworks like Apache Spark and Dask will enable more efficient large-scale data handling.
Enhanced AI and Machine Learning Integration
Python’s integration with AI and machine learning will continue to advance, with developments in deep learning, natural language processing (NLP), and automated machine learning (AutoML). These advancements will enable more sophisticated and automated data analytics solutions.
Focus on Data Privacy and Security
As data privacy and security concerns grow, Python will help address these issues. Python libraries and tools will evolve to support data privacy compliance and enhance data security measures.
Growing Importance in Edge Computing
Edge computing will become increasingly important, and Python’s capabilities in edge analytics will be pivotal. Python’s lightweight frameworks and libraries will facilitate data processing and analysis at the edge, enabling real-time insights and decision-making.
Conclusion
Python is worth considering for any data handling purposes. Python’s unique combination of adaptability means that whether you’re working with database data, Excel files, CSVs, or online data, it’s ready to serve. The language’s flexibility makes it ideal for various data analysis jobs, from data cleansing and filtering to more complex statistical analysis and machine learning.
FAQs
Python’s suitability for data analytics stems from its simplicity, extensive libraries, and strong community support. Its intuitive syntax allows for efficient coding, while libraries like Pandas and NumPy provide powerful data manipulation and analysis tools.
Python can be used for statistical analysis with libraries such as StatsModels and SciPy. These libraries offer functions for hypothesis testing, regression analysis, and other statistical techniques, enabling analysts to derive meaningful insights from data.
Python plays a significant role in data visualization with libraries like Matplotlib, Seaborn, and Plotly. These libraries allow analysts to create a wide range of visualizations, from simple plots to interactive dashboards, aiding in data interpretation and communication.
Python offers advanced analytical capabilities such as statistical analysis, machine learning, and deep learning. Libraries like Scikit-learn and TensorFlow provide tools for developing predictive models, while StatsModels supports sophisticated statistical analysis.
Python supports machine learning with libraries such as Scikit-learn, TensorFlow, and PyTorch. These libraries provide algorithms and tools for training and evaluating machine learning models, enabling analysts to build and deploy predictive models effectively.
Python’s advantages for web scraping include its ease of use, extensive libraries (e.g., BeautifulSoup, Scrapy), and strong data extraction and manipulation support. These features make Python ideal for collecting and processing data from web sources.
Python supports data visualization with libraries like Matplotlib, Seaborn, and Plotly. These libraries enable the creation of various visualizations, helping data scientists explore data, identify trends, and present insights effectively.
Python offers robust NLP capabilities with libraries like NLTK, SpaCy, and TextBlob. These tools support tokenization, named entity recognition, sentiment analysis, and part-of-speech tagging, enabling sophisticated text processing and analysis.
Python facilitates time series analysis through libraries like Pandas and StatsModels. These libraries provide tools for handling date-time data, performing decomposition, forecasting with ARIMA models, and visualizing trends, aiding in predictive analytics and trend identification.
Interactive computing in Python, via tools like Jupyter Notebooks, enhances data analysis by allowing real-time code execution, visualization, and documentation. This interactive environment fosters experimentation, immediate feedback, and a clear presentation of analysis processes and results.
Python integrates with databases using libraries like SQLAlchemy and Pandas. SQLAlchemy facilitates database interactions, while Pandas allows easy data import/export. APIs can be accessed using libraries like requests, enabling data retrieval and interaction with external services.
Python’s popularity in data science stems from its simplicity, extensive libraries (e.g., Pandas, NumPy), and strong community support. Its versatility, ease of learning, and powerful tools for data manipulation and machine learning make it a preferred choice for analysts.

Related Articles
-
 How Is Full Stack Development Booming in The IT Industry?
How Is Full Stack Development Booming in The IT Industry?Talking About How Is Full Stack Development Booming in The IT Industry? Full Stack development is about exposing a wide range of ideas. The more you expose yourself to
-
Optimizing Diagnostic Analytics with Custom Dashboards: The Data-Driven Revolution in Manufacturing
In the relentless race of modern manufacturing, speed alone doesn’t win—it’s the combination of speed, precision, and insight that defines leaders. With razor-thin margins and rising expectations, manufacturers are under
-
 A Guide to Selecting the Best Java Framework for Your Microservices
A Guide to Selecting the Best Java Framework for Your MicroservicesJava is a programming language framework for web development which was first introduced in 1995. It is a flexible framework with multiple varieties that can be used for microservices. It


